- Speech-to-text — turns your voice into text (the transcription step).
- Post-processing — an optional LLM pass that cleans up, punctuates, and formats the transcript afterwards.
Three ways to run a model
Every model — speech or post-processing — falls into one of three buckets:On-device
Runs entirely on your machine. Audio never leaves your device, works offline, and costs nothing per minute. The strongest privacy guarantee.
HyperWhisper Cloud
Built-in, no API key, no separate account. The most accurate option, billed per minute of actual speech with no markup.
Bring your own key
Plug in your own provider API key and pay that provider directly — useful if you already have credits or want a specific model.
There is no universally “best” model. On-device models are unbeatable for privacy and offline use; cloud models are noticeably more accurate on accents, noise, and technical vocabulary. The library exists so you can make that trade yourself.
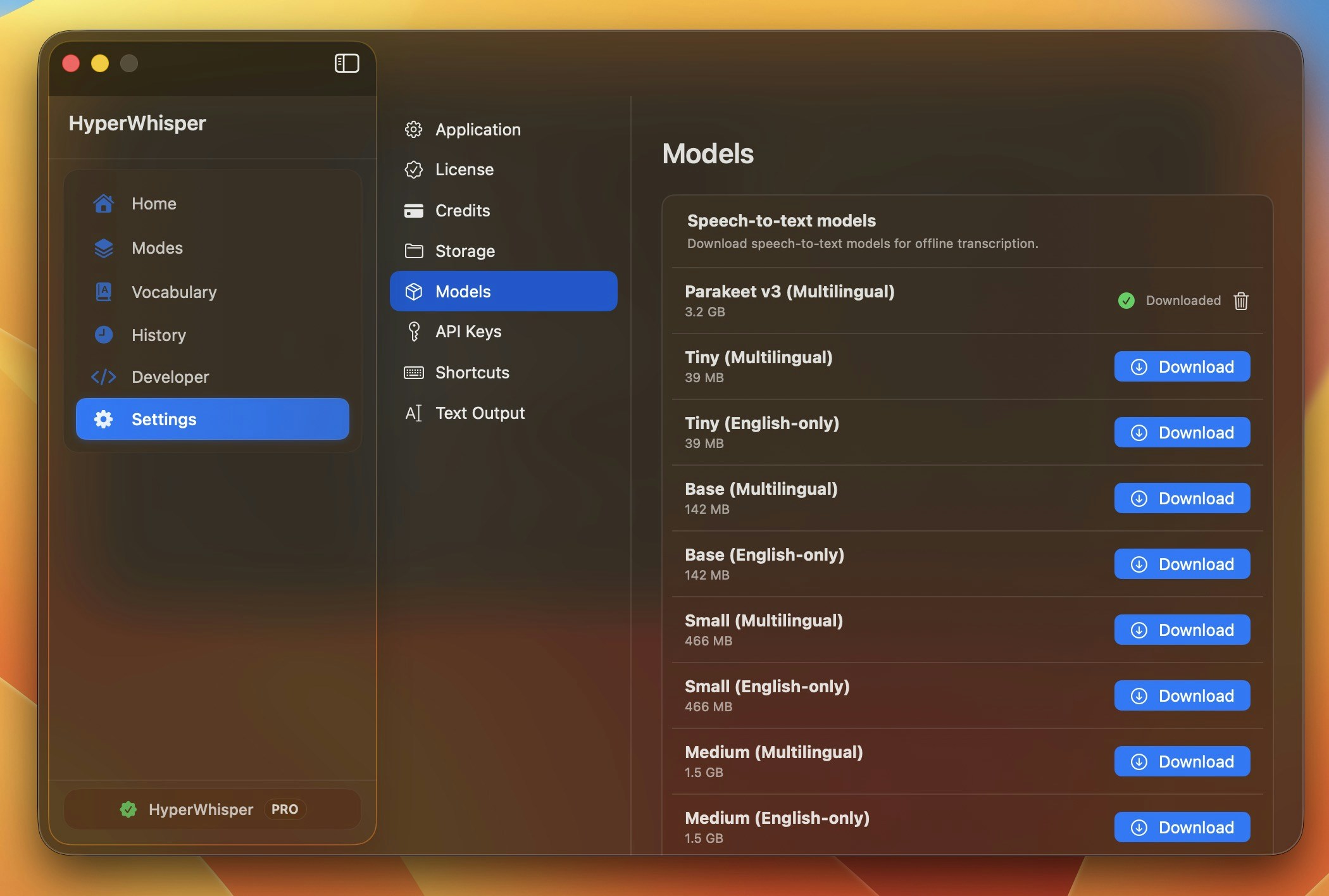
Speech-to-text models
On-device
These run locally with no network calls. Once downloaded (where applicable) they work fully offline — your audio is never uploaded anywhere. See Data Privacy for details.Whisper models
OpenAI’s general-purpose multilingual models. The VRAM values are the recommended GPU memory for full acceleration — with less, the model still runs on CPU (or partial GPU), just slower.NVIDIA Parakeet models
NVIDIA Parakeet models are typically faster than equivalent-size Whisper models and very accurate for the languages they support.
Parakeet V3 covers: English, German, Spanish, French, Italian, Portuguese, Dutch, Polish, Russian, Ukrainian, Czech, Slovak, Hungarian, Romanian, Bulgarian, Croatian, Slovenian, Serbian, Danish, Swedish, Norwegian, Finnish, Estonian, Latvian, Lithuanian.
On Windows, Parakeet runs on both x64 and ARM64, while Whisper is currently x64-only. If you’re on a Snapdragon / ARM Windows device, choose Parakeet.
NVIDIA Nemotron 3.5 models
NVIDIA’s Nemotron 3.5 ASR is the newest on-device option (macOS). It edges out the other local models on accuracy and reaches well beyond European languages — the multilingual variant is the only local model that handles Chinese, Japanese, Korean, and Arabic.Apple Speech & Qwen3 ASR
- Apple Speech is built into macOS — no download, available the moment you launch the app. It’s the quickest private option for everyday Mac dictation. (Requires a recent macOS version.)
- Qwen3 ASR is an additional multilingual on-device model (macOS) for users who want to try Alibaba’s ASR.
Offline language coverage at a glance
Not sure which local model handles your language? This table maps the common use-cases. For the full Parakeet V3 and Nemotron language lists, see the sections above.Nemotron is macOS-only. Parakeet and Whisper run on both macOS and Windows. See individual sections above for details.
HyperWhisper Cloud
HyperWhisper Cloud is built-in — no API key, no separate account. It routes to best-in-class providers behind four accuracy tiers, and you only pay for actual speech (silence and empty recordings cost 0 credits). Use it when you want the highest accuracy without any setup.
See Providers for pricing, cost examples, and per-language guidance.
Bring your own key
If you already hold API credits, want a provider’s free tier (Deepgram $200, AssemblyAI $50), or need a specific model, plug in your own key under API Keys. You pay the provider directly at their published rate. Supported providers for bring-your-own-key transcription: OpenAI · Groq · Deepgram · AssemblyAI · ElevenLabs · Mistral · Soniox · Google GeminiWhen you bring your own key, opting your audio out of model training is your responsibility — each provider has its own setting. See Data Privacy for a copy-pasteable prompt that finds the current opt-out for any provider.
Post-processing models
Post-processing is an optional second step: after transcription, an LLM cleans up filler words, fixes punctuation and capitalization, and applies any formatting your mode asks for. It’s separate from the speech model — you can mix any speech model with any post-processing model.Cloud post-processing
Available built-in through HyperWhisper Cloud (no key needed) or with your own API key.
Every cloud post-processing model is labeled with a speed and accuracy rating (explained in the Rating scale section below) so you can pick the trade-off that matters to you.
Local LLM post-processing
Local Gemma 4 models clean up and format transcript text fully offline after download — your text never leaves your device. The local LLM is powered by a bundled llama.cpp server that starts automatically when the mode needs it. Platform availability:- macOS
- Windows
Local LLM post-processing is available on Apple Silicon Macs (M1 and later). The llama.cpp server runs via Metal GPU acceleration. Intel Macs do not support local LLM post-processing — cloud post-processing providers are available as an alternative.
Rating scale
Every model in the library — speech-to-text and post-processing — shows a Speed bar and an Accuracy bar, each rated 1–5. The numbers come from an internal benchmark suite run over real recordings (results inbenchmarks/results/).
The Model Library sorts by the sum of Speed + Accuracy (descending) so the most balanced models float to the top. If you care more about one dimension than the other, you can scroll past the top recommendations to find a model that emphasizes speed or quality specifically.
Using on-device models
Downloading & storage
Open Model Library in the app, click Download on any entry, and watch the circular progress indicator. You can cancel mid-stream with the× button. Downloaded models stay on disk until you remove them.
Apple Speech is built into macOS and needs no download.
GPU vs CPU
Local engines use your GPU when available and fall back to CPU automatically if you don’t have a dedicated GPU or there isn’t enough VRAM. The model still runs on CPU — it’s just slower.Removing models
To free up disk space, click the trash icon next to any downloaded model in Model Library. The file is removed immediately and can be re-downloaded any time.Which should I pick?
Privacy is non-negotiable / offline
An on-device speech model. Apple Speech for instant Mac dictation, or Parakeet / Nemotron for higher accuracy. Audio never leaves your machine.
I want the best accuracy, no setup
HyperWhisper Cloud — Highest (ElevenLabs Scribe v2). No API key, pay only for speech.
I speak a non-European language, offline
Nemotron 3.5 (Multilingual) — on-device coverage for Chinese, Japanese, Korean, Arabic, and ~40 languages total.
Older laptop / no dedicated GPU
Whisper Tiny or Small — runs comfortably on CPU. For longer audio, switch to HyperWhisper Cloud.
English only, want it fast & local
Parakeet V2 (English) — typically faster than equivalent Whisper with comparable accuracy.
I already have a provider key
Bring your own key — plug it in and pay the provider directly. See API Keys.
Boost accuracy on any model
- Custom vocabulary — add product names, jargon, and colleagues’ names. The single biggest improvement for technical or professional use. (Support varies by model — Apple Speech and Whisper support it locally; among cloud providers most do, a few don’t.)
- Low-noise environment — every model degrades with background noise. See Best Practices.
- Natural pace — speech that’s too fast or too slow both hurt accuracy.
Go deeper
Providers
HyperWhisper Cloud tiers, per-minute pricing, cost examples, and accuracy by language.
API Keys
Set up bring-your-own-key access for any supported provider.